What are They?
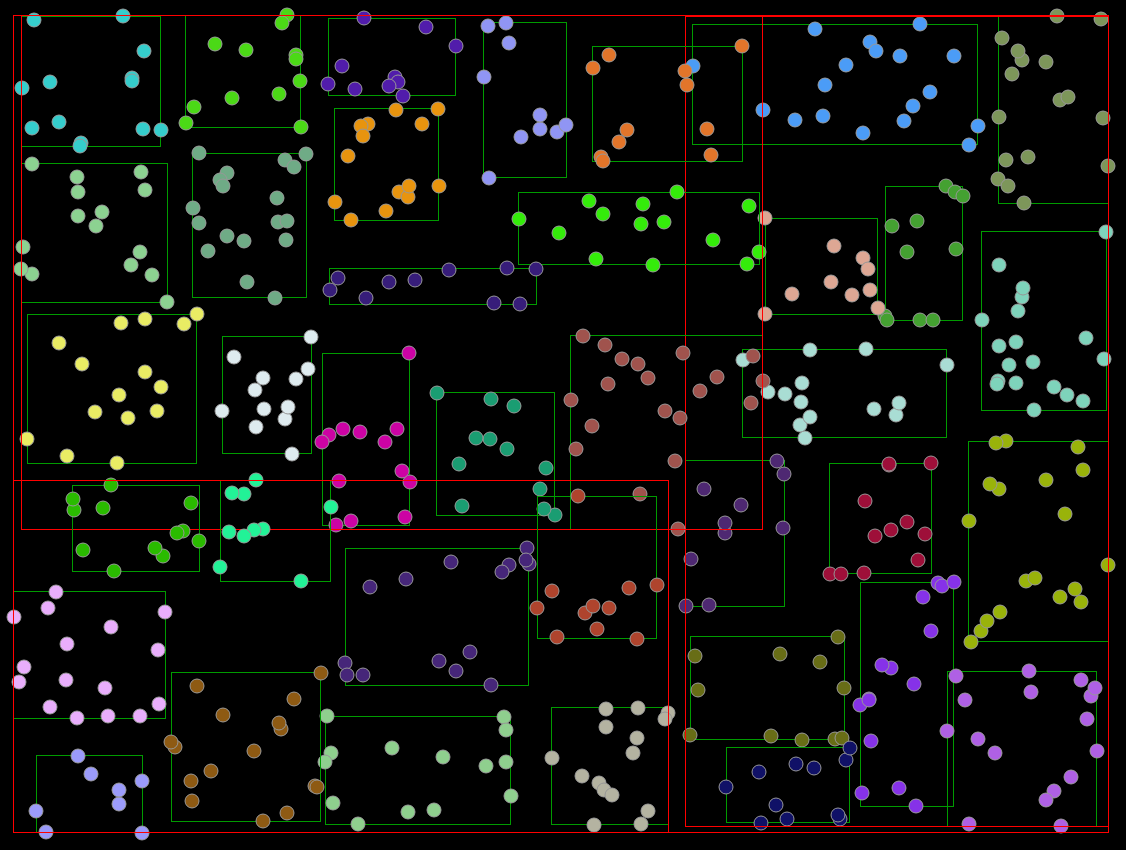
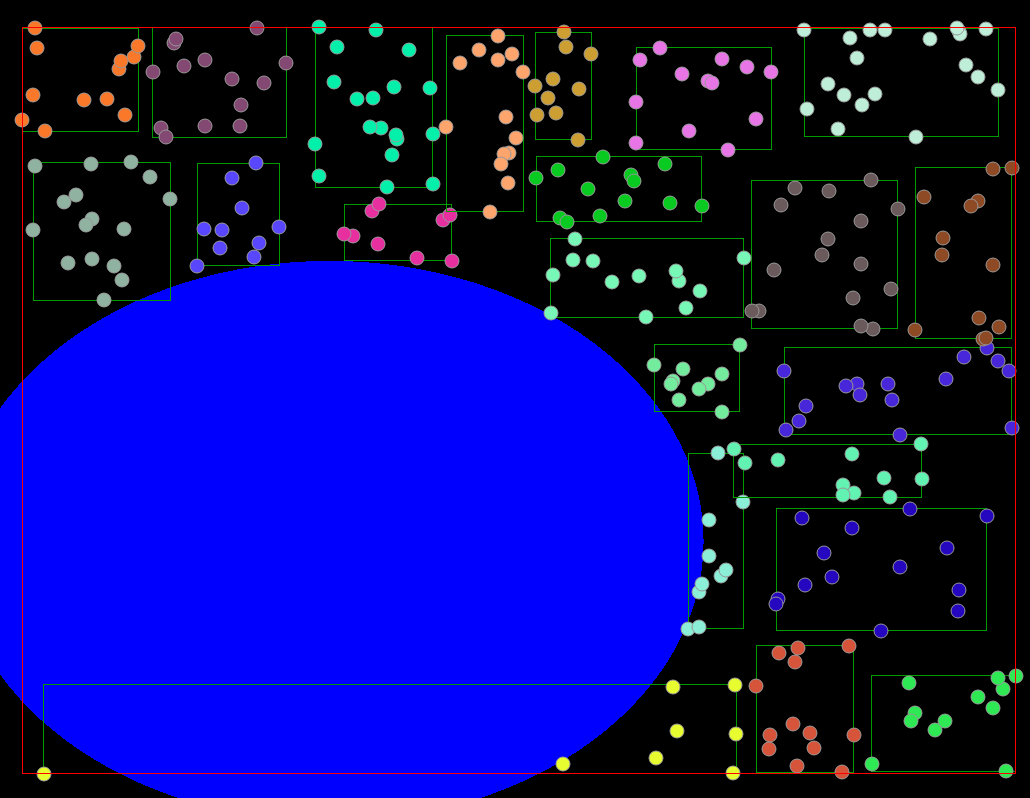
Indexing often describes methods of storing and organizing large amounts of data. In this case, spatial indexing is for the storage and querying of large amounts of spatial data, typically used in path planning and navigation. For example, map applications can store registered location data to provide the user with nearby attractions/restaurants they may want to visit.
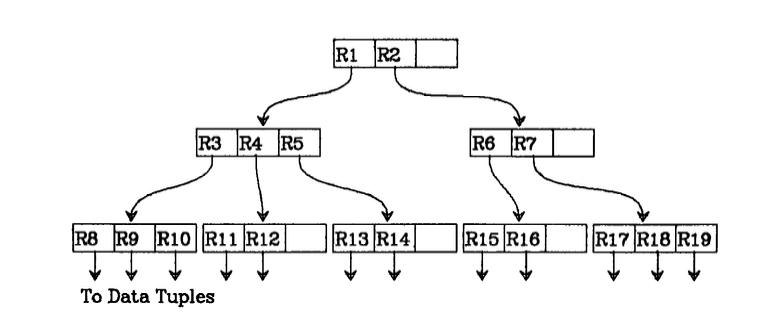
Spatial trees can be of different types, some are balanced trees (R-Trees) where they try to minimize tree depth. Others are adaptive and bound the number of children per tree node (Quad-trees, Octrees, ...).